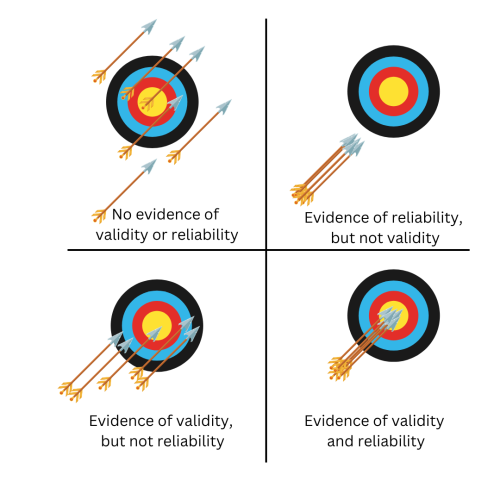
Validity in Educational Research: A Deeper Examination
Presented by Joe Tise, PhD, Senior Education Researcher at IACE
The concept of validity, including validity of educational research, has evolved over millennia. Some of the earliest examples of how validity influenced society at scale comes from the ancient Chinese Civil Service exam programs (Suen & Yu, 2006). Back in 195 BCE, Emperor Liu Bang decreed that men of virtue and ability ought to serve the nation in various capacities. With that decree, Emperor Bang established the “target” for assessment against which the effectiveness of various assessments would be judged. Assessments which could more readily select men of virtue and ability would be considered more useful than those which could not. Over the next 2,000 years, the Chinese Civil Service exam took many forms: expert observational ratings, writing poetry, drafting philosophical essays, and portfolio submissions, among other variations.
The concept of validity has been deliberated in Western cultures as well since at least the early 1900s. Early conceptions viewed validity merely as a statistical coefficient, such that even a correlation coefficient could measure validity (Bingham, 1937; Hull, 1928). You need only to examine the numerous spurious correlations demonstrated by Tyler Vigen to see that a simple correlation cannot sufficiently capture the true nature of validity. Fortunately, this reductive view of validity did not persist long–it was soon overtaken by an ancestor of present validity conceptions. By the 1950s, psychometricians detailed multiple “types” of validity, such as predictive, concurrent, construct, and content validity (American Psychological Association, 1954).
Still, this conception of validity misinterpreted the unitary nature of validity. Philosophical deliberations largely concluded in 1985 when the Joint Committee for the Revision of the Standards for Educational and Psychological Testing (Joint Committee; comprised of the APA, AERA, and NCME) established validity as one unitary construct that does not have multiple “types” but rather multiple sources of validity evidence (American Educational Research Association et al., 1985). In 2014, the Joint Committee further clarified that validity refers to the “the degree to which evidence and theory support the interpretations of test scores for proposed uses of tests” (American Educational Research Association et al., 2014). Thus, “validity” applies to our interpretations and uses of tests, not the test itself.
The contemporary view of validity details five primary sources of validity evidence, presented in the table below (in no particular order).
| Source of Validity Evidence | Description | Example of How to Assess |
|---|---|---|
| Test content | Themes, wording, and format of the items, tasks, or questions on a test | Expert judgment; delphi method; content specifications |
| Response processes | The extent to which test takers actually engage the cognitive/behavioral processes the test intends to assess | Analyze individual test responses via interviews; examine early drafts of a response (e.g., written response or math problem); eye-tracking |
| Test structure | The degree to which the relationships among test items and test components conform to the construct on which the proposed test score interpretations are based | Exploratory factor analysis; confirmatory factor analysis; differential item functioning analysis |
| Relations to other variables | Do scores on the test relate in the expected way to other variables and/or other tests of the same construct? | Correlate test scores with other variables; regress test scores on other variables |
| Test consequences | Must evaluate the acceptability of (un)intended consequences from interpretations and uses of the test scores | Does the test incentivize cheating? Are certain subgroups systematically harmed by the test? |
I will note here that although there are multiple sources of validity evidence, a researcher does not necessarily have to provide evidence from all sources for a given test or measure. Some sources of validity evidence will not be relevant to a test.
For example, evidence of test structure is largely nonsensical for a simple one or two-item “test” of a person’s experience with, say, teaching computer science (e.g., asking someone how many years of experience they have in computer science). Similarly, a measure of someone’s interest in computer science likely does not require evidence based on response processes, because reporting interest in a topic does not really invoke any cognitive or behavioral processes (other than reflection/recall, which is not the target of the test).
References
American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (1985). Standards for educational and psychological testing. Author.
American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for Educational and Psychological Testing. American Educational Research Association.
American Psychological Association. (1954). Technical recommendations for psychological tests and diagnostic techniques. Psychological Bulletin, 51(2), 1–38. https://doi.org/10.1037/h0053479
Bingham, W. V. (1937). Aptitudes and aptitude testing (pp. viii, 390). Harpers.
Hull, C. L. (1928). Aptitude Testing (L. M. Terman, Ed.). World Book Company.https://doi.org/10.1086/498328
Suen, H. K., & Yu, L. (2006). Chronic Consequences of High‐Stakes Testing? Lessons from the Chinese Civil Service Exam. Comparative Education Review, 50(1), 46–65. https://doi.org/10.1086/498328